

実際にエルメスオンラインでカバンを手に入れることができたので、そのために開発した在庫更新通知BOTの開発についてをここに記しておきます。
まず、エルメスオンラインの自動購入BOTなるものを作ろうと考え、Redditでガイジンがやってるだろうと情報を集めたが、結論からして無理という結果に至っていた。
まあ天下のエルメス様なのでただのオンラインショップではないとは思っていたが。。。
しかし、エルメスオンラインのUSに限り、在庫更新通知サービスというものが存在していた。登録してみたが実態はあまり実用的ではなく、精度もイマイチ、通知タイミングも即座ではなさそうだった。
そして実際に手作業で読み込みを何度も行い在庫更新を待ってみると、なんとロボットじゃないか?と疑われ、パズルが表示される。しかもこれを完成させてロボットじゃないよと示しても、数回やるだけでセキュリティブロックされ、一定期間、サイトの表示ができなくなる。
あと単純な再読み込みではキャッシュが残っており、商品が更新されていたとしても表示されない。

スマホなら4G回線にしてIPアドレス変えていけるかと思われたが、それでもブロックされる。キャッシュやCookieを削除して4G回線繋ぎ直して初めて表示される。
ただこれも確実ではない。なぜかブロックされる場合もある。
このように基本的にはBOT対策でCaptchaを実装しているのがほとんどである。
Captchaにもいろんな種類があり、今回のエルメスオンラインには「DataDome」という種類のCaptchaが組み込まれている。(調べ方は割愛)
次に、エルメスオンラインの通信を調べて、どうやってサイトが表示されるかを理解する。
普通に考えれば、商品情報を管理するバックエンドサーバが存在し、フロントのサーバとは分けることで安全な商品管理を行う。というのが常人の考えで、タチの悪い変態は、ごにゃごにゃしてバックエンドを隠す輩もいる。
エルメスオンラインは常人のようで安心した。
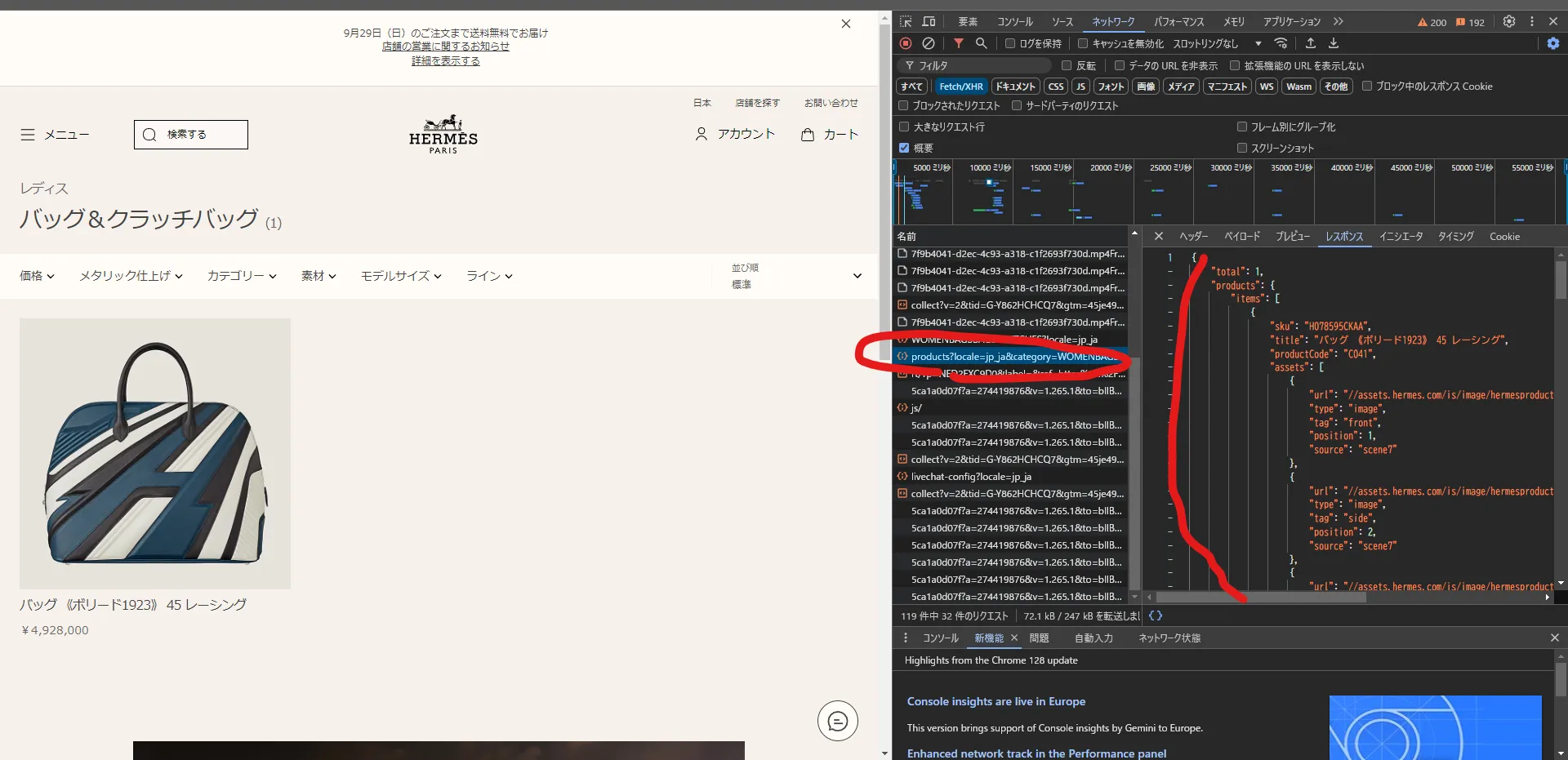
https://bck.hermes.com/products?locale=jp_ja&category=WOMENBAGSBAGSCLUTCHES&sort=relevance&pagesize=48&available_online=false
これがエルメスオンラインの在庫商品情報を管理するバックエンドから情報を引き出しているAPIのようである。
こいつを直接叩けるか検証してみると、簡単に叩けてしまう。
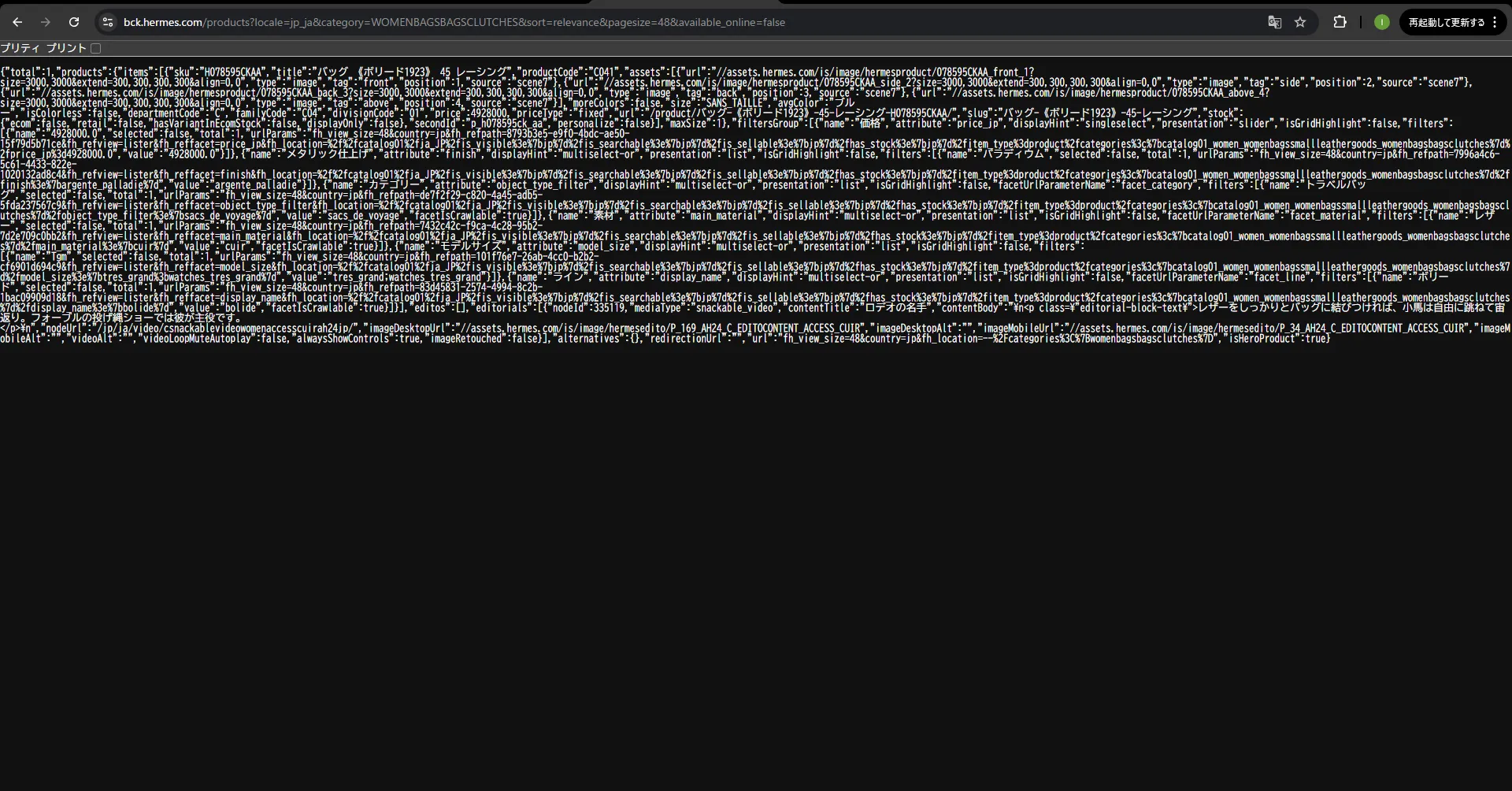
こりゃイージーだな。なので、直接APIを5秒に一回叩いて情報を取得するプログラムを組んで勝ちだな。以下に一部コードを抜粋
# Chromeオプションの設定
options = Options()
# options.add_argument("--headless") # ヘッドレスモードで起動
options.add_argument("--incognito") # シークレットモードで起動
options.add_argument("--disable-cache") # キャッシュを無効化
options.add_argument("--disable-extensions") # 拡張機能を無効化
options.add_argument(
"--disable-gpu"
) # GPUレンダリングを無効化(ヘッドレスモードでは不要)
options.add_argument("--no-sandbox") # サンドボックスを無効化
options.add_argument("--disable-dev-shm-usage") # /dev/shmの使用を無効化
# Chromeドライバーのパスを指定してブラウザを起動
driver = webdriver.Chrome(options=options)
# 指定されたURLにアクセス
urls = [
"https://bck.hermes.com/products?urlParams=fh_view_size=48%26country=jp%26fh_refpath=de7f2f29-c820-4a45-adb5-5fda237567c9%26fh_refview=lister%26fh_reffacet=object_type_filter%26fh_location=%252f%252fcatalog01%252fja_JP%252fis_visible%253e%257bjp%257d%252fis_searchable%253e%257bjp%257d%252fis_sellable%253e%257bjp%257d%252fhas_stock%253e%257bjp%257d%252fitem_type%253dproduct%252fcategories%253c%257bcatalog01_women_womenbagssmallleathergoods_womenbagsbagsclutches%257d&locale=jp_ja&category=WOMENBAGSBAGSCLUTCHES&sort=relevance&pagesize=48&available_online=false",
"https://bck.hermes.com/products?urlParams=fh_view_size=48%26country=jp%26fh_refpath=de7f2f29-c820-4a45-adb5-5fda237567c9%26fh_refview=lister%26fh_reffacet=object_type_filter%26fh_location=%252f%252fcatalog01%252fja_JP%252fis_visible%253e%257bjp%257d%252fis_searchable%253e%257bjp%257d%252fis_sellable%253e%257bjp%257d%252fhas_stock%253e%257bjp%257d%252fitem_type%253dproduct%252fcategories%253c%257bcatalog01_women_womenbagssmallleathergoods_womenbagssmallleather%257d&locale=jp_ja&category=WOMENBAGSSMALLLEATHER&sort=relevance&pagesize=48&available_online=false",
"https://bck.hermes.com/products?urlParams=fh_view_size=48%26country=jp%26fh_refpath=de7f2f29-c820-4a45-adb5-5fda237567c9%26fh_refview=lister%26fh_reffacet=object_type_filter%26fh_location=%252f%252fcatalog01%252fja_JP%252fis_visible%253e%257bjp%257d%252fis_searchable%253e%257bjp%257d%252fis_sellable%253e%257bjp%257d%252fhas_stock%253e%257bjp%257d%252fitem_type%253dproduct%252fcategories%253c%257bcatalog01_joailleriemontres_bijouterie_bijouterieargent%257d&locale=jp_ja&category=BIJOUTERIEARGENT&sort=relevance&pagesize=48&available_online=false",
]
for i in range(len(urls)):
driver.execute_script("window.open('');")
driver.switch_to.window(driver.window_handles[-1])
driver.get(urls[i])
# ページのHTMLを取得
html_content = driver.page_source
# BeautifulSoupを使ってHTMLを解析
soup = BeautifulSoup(html_content, "html.parser")
# <pre>タグ内のテキストを取得
pre_tag = soup.find("pre")
pre_content = ""
if pre_tag:
pre_content = pre_tag.text
else:
print(f"HP : <pre>タグが見つかりませんでした")
send_line_notify2("HP : preタグが見つからへんぞ。")
time.sleep(60)
break
# JSONとしてパース
json_data = json.loads(pre_content)
with open(current_item_bag, "w", encoding="utf-8") as output_file:
# 最新商品情報を格納
current_items = {
item["sku"]: {"title": item["title"], "url": item["url"]}
for item in json_data["products"]["items"]
}
# SKUとタイトルをファイルに書き込み
for sku, data in current_items.items():
title = data["title"]
output_file.write(f"{sku} : {title}\n")
# current_items.txtとlast_items.txtを比較
if file_content_is_different(current_item_bag, last_item_bag):
# 更新前の商品情報を格納
with open(last_item_bag, "r", encoding="utf-8") as last_file:
# SKUのみを抽出
last_skus = [
line.split(" : ")[0]
for line in last_file.read().splitlines()
if " : " in line
]
# 更新されたアイテムのSKUをリストアップ
updated_items = [
sku for sku in current_items.keys() if sku not in last_skus
]
# 削除されたアイテムのSKUをリストアップ
removed_items = [
sku for sku in last_skus if sku not in current_items.keys()
]
if updated_items:
for sku in updated_items:
title = current_items[sku]["title"]
# 「ピコタン」が含まれているかチェック
if "ピコタン" in title:
# 「ピコタン」が含まれている場合の処理
message_pico = f"\nおいおい!!ピコタンあるよ!!!!\n取られるな!\n\n商品名: {title}\n"
encoded_url = urllib.parse.quote(current_items[sku]["url"])
message_pico += product_before_url + encoded_url
send_line_notify(message_pico)
# LINEで通知を送信
message = (
f"\nHPが検知:カバンに新しい商品が追加されました。\n{front_url_bag}\n\n"
)
message += "【更新された商品】\n"
for sku in updated_items:
title = current_items[sku]["title"]
message += f"{title}\n"
message += "\n-- 現在の掲載商品 --"
for sku, data in current_items.items():
title = data["title"]
message += "\n" + title
send_line_notify(message)
ちなみに、”notificationDisabled”: Trueをdataに加えると、通知なしでメッセージ送れるから、エラー系の通知はそうしてる。
def send_line_notify(message):
url = "https://notify-api.line.me/api/notify"
headers = {"Authorization": f"Bearer {line_notify_token}"}
data = {"message": message}
response = requests.post(url, headers=headers, data=data)
return response
あとはファイル書き込み更新したり、sssleniumのタブ閉じたりってコードがあったり、7:45 ~ 22:45までしか稼働しないようなコードがあったりする。
実際にはこういう感じで動作する。
これは勝ったな。そう思っていたところやつが現れた。そう、Captcha様だ。
こりゃ参った、バックエンドにも仕込んでやがった。まあ常識的に考えればそうだよな。
これを踏まえると方法は2つ。
1つはそもそもCaptchaを表示させないようにする。もう1つはCaptchaを突破するプログラムを作る。
まずはCaptchaをそもそも表示させないよう、回避する方法を考えた。
Captchaが表示されるときは、まずデバイス検証が行われる。デバイス検証が行われるのはなぜか。同じIPアドレス上から複数回のリクエストが発生したからだと考えた。
なら、IPアドレスを変えればいいんじゃね?と安直に思ったが、そのために4G回線を使ったスマホの自動操作を行うわけには行かないし、自宅のグローバルIPアドレスは基本固定なので、強制的に自宅のIPアドレスを変更することにした。
方法は簡単でルータのリセットだ。契約内容にもよるが、ルータをリセットすると、ISPによって自動でIPが割り当てられる。なので、Captchaが表示されたのを検知し、ルータを自動でリセットする操作をプログラムで実装した。
# <pre>タグ内のテキストを取得
pre_tag = soup.find("pre")
iframe_tag = soup.find("iframe")
if pre_tag:
pre_content = pre_tag.text
elif iframe_tag:
print(f"パズル表示")
send_line_notify2("パズル表示されました。ルーターを再起動します。")
driver.close() # そのタブを閉じる
driver.switch_to.window(driver.window_handles[0]) # 最初のタブに戻る
reset_router(driver)
continue
else:
print(f"preタグもiframeもないのでネットワークエラー?")
send_line_notify2("preタグもiframeもないのでネットワークエラー?")
driver.close() # そのタブを閉じる
driver.switch_to.window(driver.window_handles[0]) # 最初のタブに戻る
continue
def reset_router(driver):
driver.execute_script("window.open('');")
driver.switch_to.window(driver.window_handles[-1])
driver.get("http://192.168.10.1/index.php")
try:
# input要素をIDで特定して、テキストを入力
input_field_admin = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "loginusr"))
)
input_field_admin.clear() # 既存のテキストをクリア
input_field_admin.send_keys("ここにユーザ名") # 任意のテキストを入力
# input要素をIDで特定して、テキストを入力
input_field_pw = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "loginpwd"))
)
input_field_pw.clear() # 既存のテキストをクリア
input_field_pw.send_keys("ここにぱすわーど") # 任意のテキストを入力
# XPATHを使ってボタンを特定しクリック
login_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//a[text()='ログイン']"))
)
login_button.click()
time.sleep(0.3)
driver.get("http://192.168.10.1/reboot_main.php")
# XPATHを使ってボタンを特定しクリック
reboot_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//a[text()='再起動']"))
)
reboot_button.click()
check_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "btn_ok"))
)
check_button.click()
time.sleep(80)
# XPATHを使って、特定のクラスとテキストを持つ<a>要素を特定し、クリックする
ok_button = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, "//a[@class='btn red medium' and text()='OK']"))
)
ok_button.click()
time.sleep(15)
driver.close() # そのタブを閉じる
driver.switch_to.window(driver.window_handles[0]) # 最初のタブに戻る
except Exception as e:
print(f"Error occurred: {e}")
やってるのは簡単なことで、seleniumでAPIをブラウザから叩きつつ、captchaが表示されたら、ルータの管理画面行って再起動ボタンを押すってだけ、あとは再起動の時間待ってあげて自動でネットワークが接続されるのでOK。ルータはNEC系です。
しかし、これではルータリセットに時間がかかるのと、なぜかCaptchaは不定期に表示されるようになった。
こりゃ面倒だ。じゃあプロキシ挟んでアクセスすりゃええんやない?と思って、無料のプロキシを提供しているサイトからアクセスするようにプログラムを組んだ。
def enter_text_in_input_field(driver, text):
try:
# input要素をIDで特定して、テキストを入力
input_field = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "url"))
)
input_field.clear() # 既存のテキストをクリア
input_field.send_keys(text) # 任意のテキストを入力
except Exception as e:
print(f"Error occurred: {e}")
def click_submit_button_and_wait_for_pre(driver):
try:
# ボタン要素をIDで特定してクリック
submit_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "requestSubmit"))
)
submit_button.click()
# <pre>タグが表示されるまで最大20秒待機
pre_tag = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.TAG_NAME, "pre"))
)
# print("<pre>タグが見つかりました。")
except Exception as e:
# print(f"Error occurred: {e}")
print("ボタン押下時か押下後の取得中にエラー、多分パズル出てる。")
for i in range(len(urls)):
driver.execute_script("window.open('');")
driver.switch_to.window(driver.window_handles[-1])
driver.get("https://www.croxyproxy.rocks/")
enter_text_in_input_field(driver, urls[i])
click_submit_button_and_wait_for_pre(driver)
# driver.get(urls[i])
# ページのHTMLを取得
html_content = driver.page_source
# BeautifulSoupを使ってHTMLを解析
soup = BeautifulSoup(html_content, "html.parser")
この手のサイトは複数あって、URLを入れるとプロキシ経由でアクセスして結果を表示してくれる。
これは結構いける。Captchaが表示されることは多々あるが、ルータリセットよりは格段に早い。しかし、API1回叩くのに、約20~30秒、Captchaが表示されれば50 秒ほどかかる。
それに無料プロキシは信頼度が低く、短時間では数に限りがあるため、20分ほどでほぼ全てのプロキシがブロックされてしまう。
5分に一回の在庫確認くらいのシステムには支障がないかもしれないが、最低でも5秒に1回は在庫確認しないと負ける。
エルメスオンラインはそういう世界だ。
なのでこの方法は打ち切り。AWSのEC2でインスタンスを立ててsquidでプロキシサーバを立てる方法もあった。
ここまでの体感、10分ほどでCaptchaが検知してブロックされブロック解除が数時間~1日かかるので、プロキシの数は幾つ必要なのか、そうするとインスタンスの数がバカにならんし、Lambdaとか使ってインスタンス再起動させてIP変更する手もあったが、時間がかかりすぎる。
すると結局コストの問題にぶち当たるのでちょっと試して断念した。
次に、ポケットWifiとかなら、リセット早いし4G回線だからいいんじゃね?ってなって早速注文してプログラムを組んだ。ポケットWifiは楽天 Wifi Pocket Platinumを使用。
def reset_router(driver):
driver.execute_script("window.open('');")
driver.switch_to.window(driver.window_handles[-1])
driver.get("http://192.168.10.1/login.php")
try:
# input要素をIDで特定して、テキストを入力
input_field_admin = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "input_user"))
)
input_field_admin.clear() # 既存のテキストをクリア
input_field_admin.send_keys("ここにユーザー目にユーザ名") # 任意のテキストを入力
# input要素をIDで特定して、テキストを入力
input_field_pw = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "input_password"))
)
input_field_pw.clear() # 既存のテキストをクリア
input_field_pw.send_keys("ここにパスワード") # 任意のテキストを入力
# XPATHを使ってボタンを特定しクリック
login_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//a[text()='ログイン']"))
)
login_button.click()
time.sleep(0.5)
# デバイス設定に移動
device_setting_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "shut_down"))
)
device_setting_button.click()
time.sleep(1.5)
# iframeに切り替え
WebDriverWait(driver, 10).until(
EC.frame_to_be_available_and_switch_to_it((By.CSS_SELECTOR, "iframe"))
)
# 再起動ボタンを特定しクリック
reboot_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "restart"))
)
reboot_button.click()
# 元のHTMLコンテキストに戻る
driver.switch_to.default_content()
check_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "submitBtn"))
)
check_button.click()
time.sleep(50)
# XPATHを使って、ログインボタンを検知し、ログイン画面に遷移したことを確認
ok_button = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, "//a[text()='ログイン']"))
)
# なんとなくクリック
ok_button.click()
time.sleep(1)
driver.close() # そのタブを閉じる
driver.switch_to.window(driver.window_handles[0]) # 最初のタブに戻る
except Exception as e:
print(f"Error occurred: {e}")
driver.close() # そのタブを閉じる
driver.switch_to.window(driver.window_handles[0]) # 最初のタブに戻る
楽天のポケットWi-Fiの管理画面がiframeで表示切替していたので、webdriver使って切り替えが必要。
まあまあいける。しかし、Captchaは手強い。何度も表示され、5分に数回リセットされる始末。これではいくらリセットが早いと言えど、30秒ほどかかっているので、勝てない。
一旦、Captchaを回避するのは諦めた。
次にCaptchaの突破を試みた。画像認識とPythonのPyguiautoなどでできるが、処理時間がどれだけかかるか。。。
そこで、同じゼミの最狂の開発者「ITO」に訪ねてみた。
すると彼も同じようなことをしようとしていたらしい。そして結論、開発は断念したとのことだったが、途中までは「2captcha」というCaptcha突破サービスを使用していたとのこと。
2captchaは簡単にいうと、captchaを突破したい人と、単純作業で稼ぎたい人をマッチングさせるシステムで、captchaのURLとパラメータとかさえわかれば、誰でもそのCaptchaを解決できてレスポンスを受け取れるので、結局は人の手で解決していることになる。(説明下手ですね。詳細は各自で調べて)
ほんならこれ使ってみようと、早速課金してやってみる。
事前に入手したエルメスのCaptchaのURLを使用してテストする。
レスポンスでCookieが返るので、そのCookieを組み込みSeleniumなどでブラウザを開き表示させるコードを書く。Datadomeの2captchaではプロキシIPが必須なので、AWSのEC2でsquidを使用しプロキシサーバを立ててあげてからやってね。(そこは割愛)
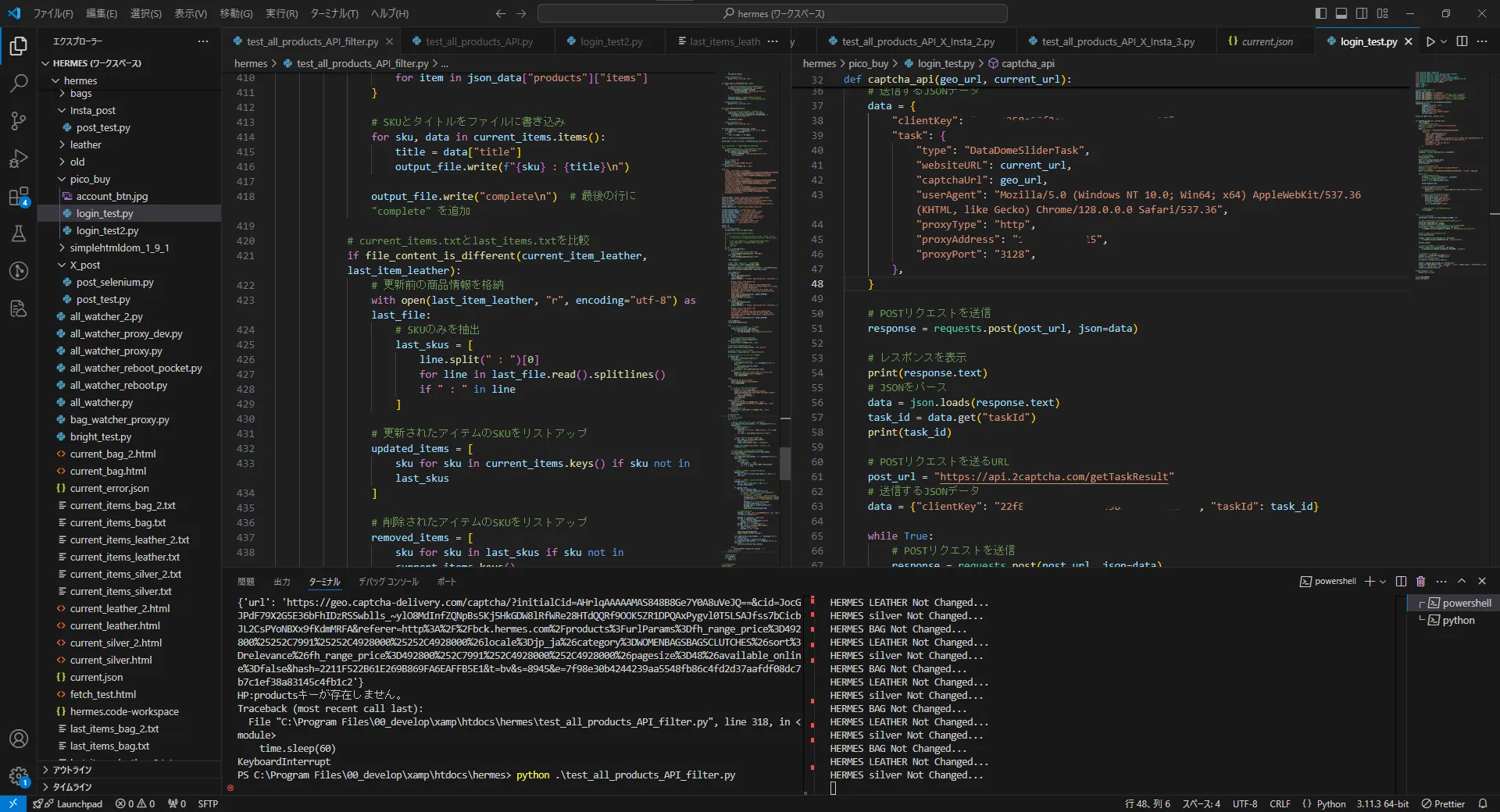
def captcha_api(geo_url, current_url):
time.sleep(5)
# POSTリクエストを送るURL
post_url = "https://api.2captcha.com/createTask"
# 送信するJSONデータ
data = {
"clientKey": "ここにクライアントキー",
"task": {
"type": "DataDomeSliderTask",
"websiteURL": current_url,
"captchaUrl": geo_url,
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
"proxyType": "http",
"proxyAddress": "ここにプロキシIP",
"proxyPort": "3128",
},
}
# POSTリクエストを送信
response = requests.post(post_url, json=data)
# レスポンスを表示
print(response.text)
# JSONをパース
data = json.loads(response.text)
task_id = data.get("taskId")
print(task_id)
# POSTリクエストを送るURL
post_url = "https://api.2captcha.com/getTaskResult"
# 送信するJSONデータ
data = {"clientKey": "ここにクライアントキー", "taskId": task_id}
while True:
# POSTリクエストを送信
response = requests.post(post_url, json=data)
# レスポンスをJSONとしてパース
result = json.loads(response.text)
print(response.text)
# errorIdが0以外の場合、Noneを返す
if result.get("errorId") != 0:
print("Error occurred:", result.get("errorDescription", "Unknown error"))
return None
# statusがreadyの場合、cookieを返す
if result.get("status") == "ready":
print(result.get("solution"))
solution = result.get("solution")
print(solution.get("cookie"))
# 'cookie' の値を取得
return solution.get("cookie")
# 5秒待機してから再度リクエストを送信
time.sleep(5)
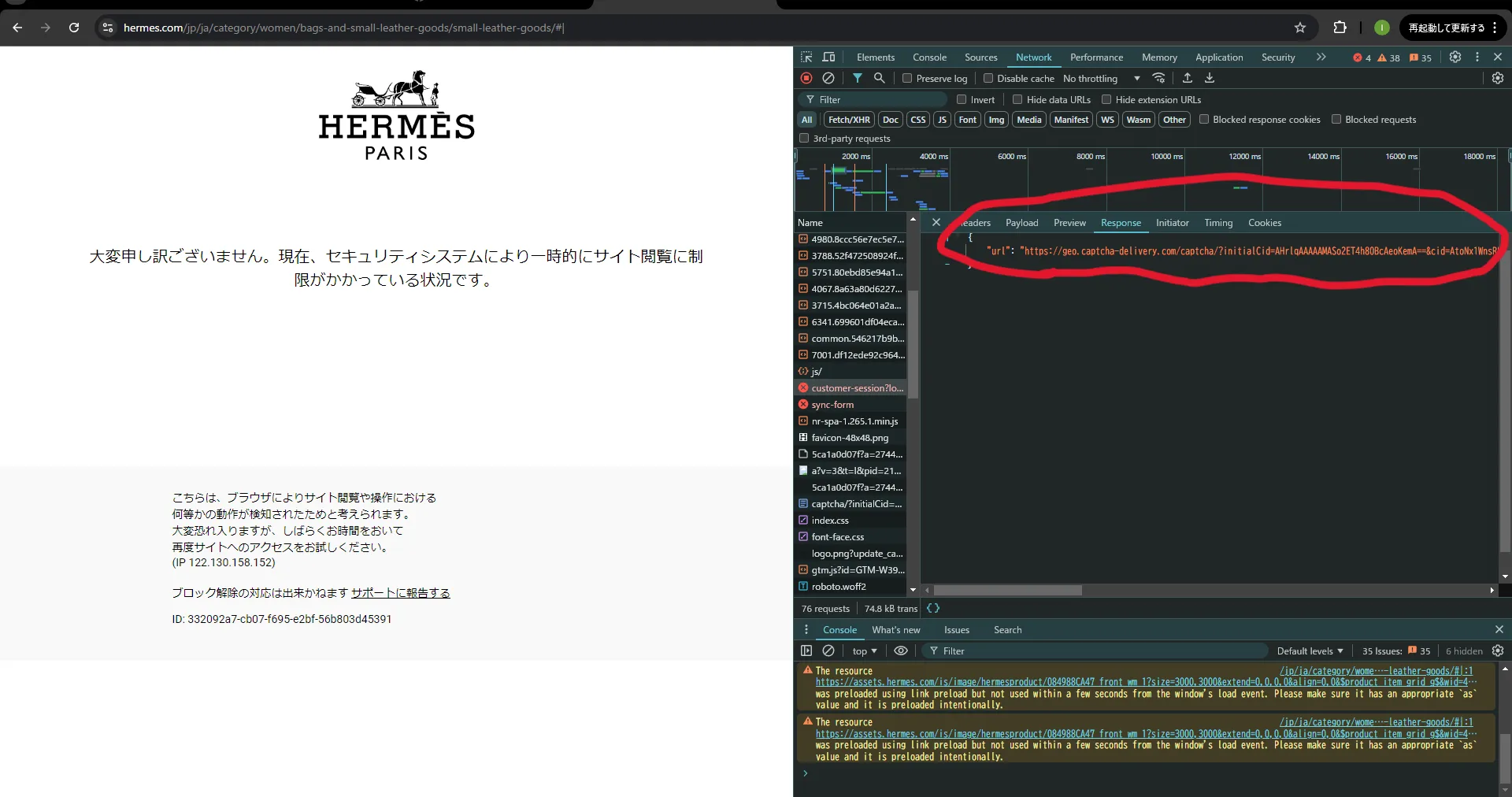
すると、Cookieは正常に帰ってくるが、そのCookieを用いてアクセスしてもなぜかセキュリティが働きブロックされる。
レスポンスを見ると、パラメータに「t=bv」があるため、IPアドレスがブロックされている。以下レスポンスと参考資料
{
"status": 200,
"cookie": "datadome=0AmHpWS7d4kMhPYS~HB3SKS9~yZ7eJE8TSNcg9aGVGGhu_~f6vWeC4GfbGaWaiMdUhdQsl5fZOcLyAiJAKG1sqlGdvXUoMZ1f9Z9dLa_xelGfbWk~Py4A7Enq~kIimz2; Max-Age=31536000; Domain=.hermes.com; Path=/; Secure; SameSite=Lax"
}
{
"url": "https://geo.captcha-delivery.com/captcha/?initialCid=AHrlqAAAAAMA4OXeDSW_irMA8uVeJQ==&cid=qUL8aw1isGedU4zIVtXUa7rjKAHXfLQ2JeOfhxIyamRL2VEsPpAOR_Y7d2V7V0oXR_IvSAEdw26FQEsq~zqsR5Jp331RpO4s9nGEhryOTu~yAYkZKtv4xoDTjUfocL1m&referer=http%3A%2F%2Fbck.hermes.com%2Flivechat-config%3Flocale%3Djp_ja&hash=2211F522B61E269B869FA6EAFFB5E1&t=bv&s=8945&e=6d181018b375e731425e5dcd44b2f7191794e3c45c8572200b232deafae7e822"
}

さあ、これでは突破できない。
まあだろうと思った。この後Datadomeのブロックは何をもとに判断しているのかを調べた。そうすると以下の内容が見つかった。

デバイスチェックが走るとき、画面の情報(サイズ、解像度など)とかCPUとかGPUのハードウェア情報まで収集して判断すると。まじかこいつ。ハードウェアは改ざん不可能だろうと思い、ITO氏もカオスだと言っているのでもうDatadomeの突破は諦めた。

ITO氏の言う通りdocker立てまくってやるとかいう方法もありますが、それは後に検証しましょ。
次はCaptchaを表示させない方法だ。
これが現状の成功した方法になる。ただ、この方法はちょっと秘密にさせてほしい。ネットでは同じようにエルメスの更新通知BOTを血眼で作っている人もいるので、それだけ価値があるという認識でいるためである。
少しだけ情報を公開すると、参照ポリシーを突破できるAPIアクセスは何があるかを考えてみると突破口になるかも。あとは物理的にごり押しする方法もある。
{kind=link}
{kind=link}
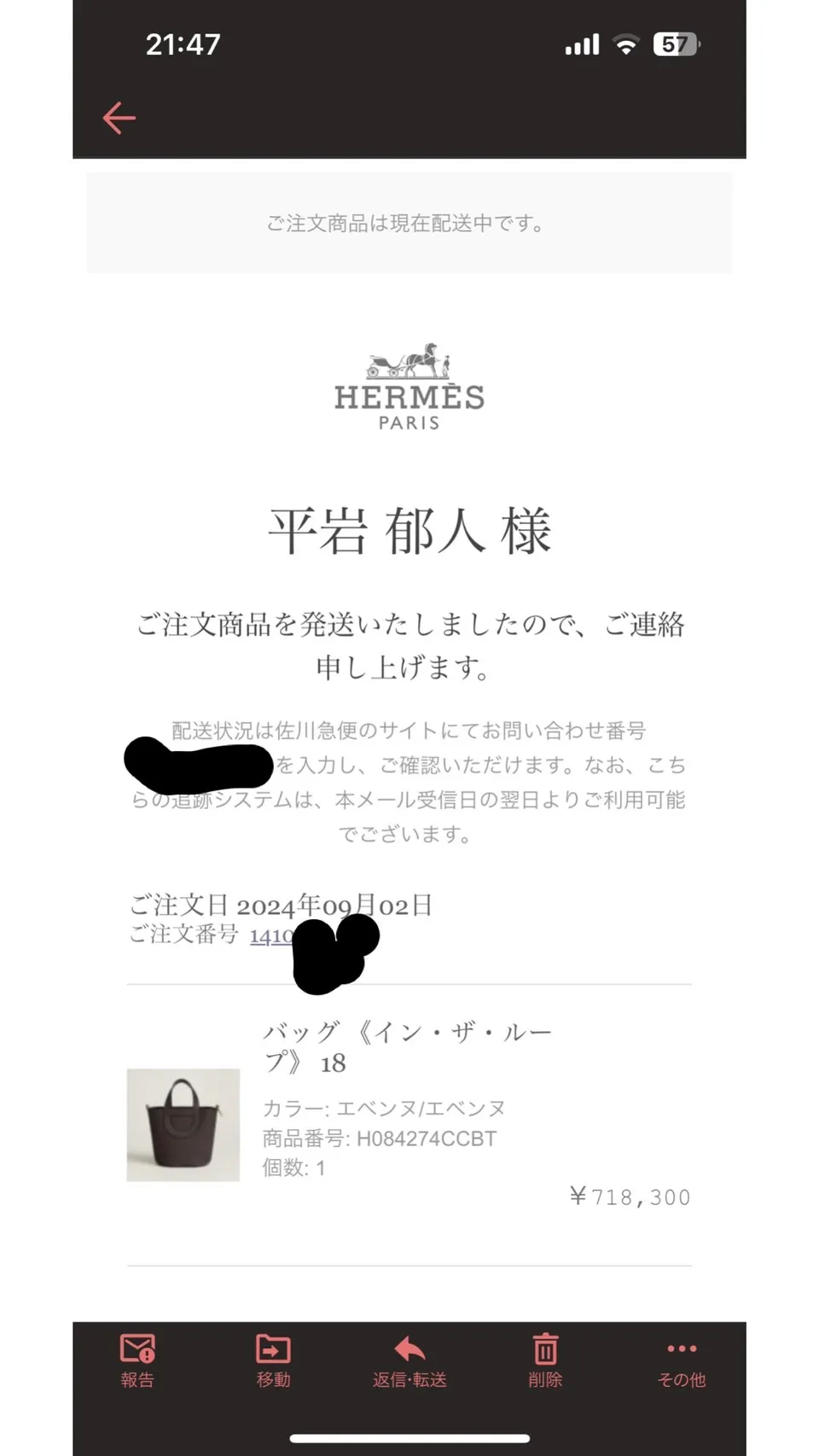
そんなこんなで、実際に成功した運用で「インザループ18」を手に入れることに成功しました。ただ、本命はピコタンなので、そいつも手に入れたいですね。
現状、システムにはいくつか課題があるので、日々戦いは続いています。
{kind=link}
{kind=link}
あと、ひっそりSNSで更新情報を自動で投稿するシステムもついでに作りました。これは完全に趣味と慈善活動です。
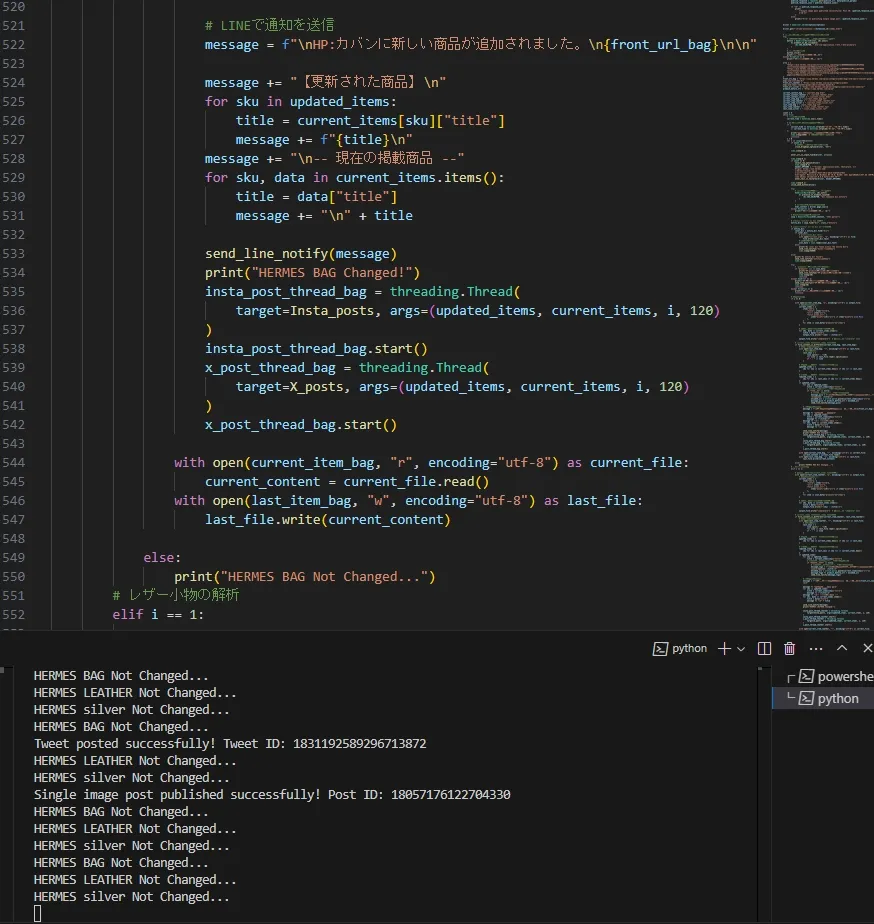
とりあえず。これで妻はほぼ全身エルメスになったわけです。一方、そもそもエルメスを買うお金はどこからでているのか?ということですが、僕のお小遣いです。月2万円です。
当然足りるわけがないので、前借していますが、現状では65年間は僕のお小遣い無しです。
このシステム、だれか買ってください。250万円からで売ります。
以上、死闘の結果でした。